[1] 3[1] 3Lecture 6
Duke University
STA 199 - Spring 2024
2024-02-01
Go to your ae repo, click Pull to get today’s application exercise to get ready for later.
Questions from the prepare materials?
ae-04-flights-wranglingGo to the project navigator in RStudio (top right corner of your RStudio window) and open the project called ae.
Open the file called ae-04-flights-wrangling.qmd and render it.
+, and indent the next line.| operator | definition |
|---|---|
< |
is less than? |
<= |
is less than or equal to? |
> |
is greater than? |
>= |
is greater than or equal to? |
== |
is exactly equal to? |
!= |
is not equal to? |
| operator | definition |
|---|---|
x & y |
is x AND y? |
x \| y |
is x OR y? |
is.na(x) |
is x NA? |
!is.na(x) |
is x not NA? |
x %in% y |
is x in y? |
!(x %in% y) |
is x not in y? |
!x |
is not x? (only makes sense if x is TRUE or FALSE) |
Let’s make a tiny data frame to use as an example:
Do something and show me
Do something, save result, overwriting original
Do something, save result, overwriting original when you shouldn’t
Do something, save result, overwriting original
data frame
“Tidy datasets are easy to manipulate, model and visualise, and have a specific structure: each variable is a column, each observation is a row, and each type of observational unit is a table.”
Tidy Data, https://vita.had.co.nz/papers/tidy-data.pdf
Note: “easy to manipulate” = “straightforward to manipulate”
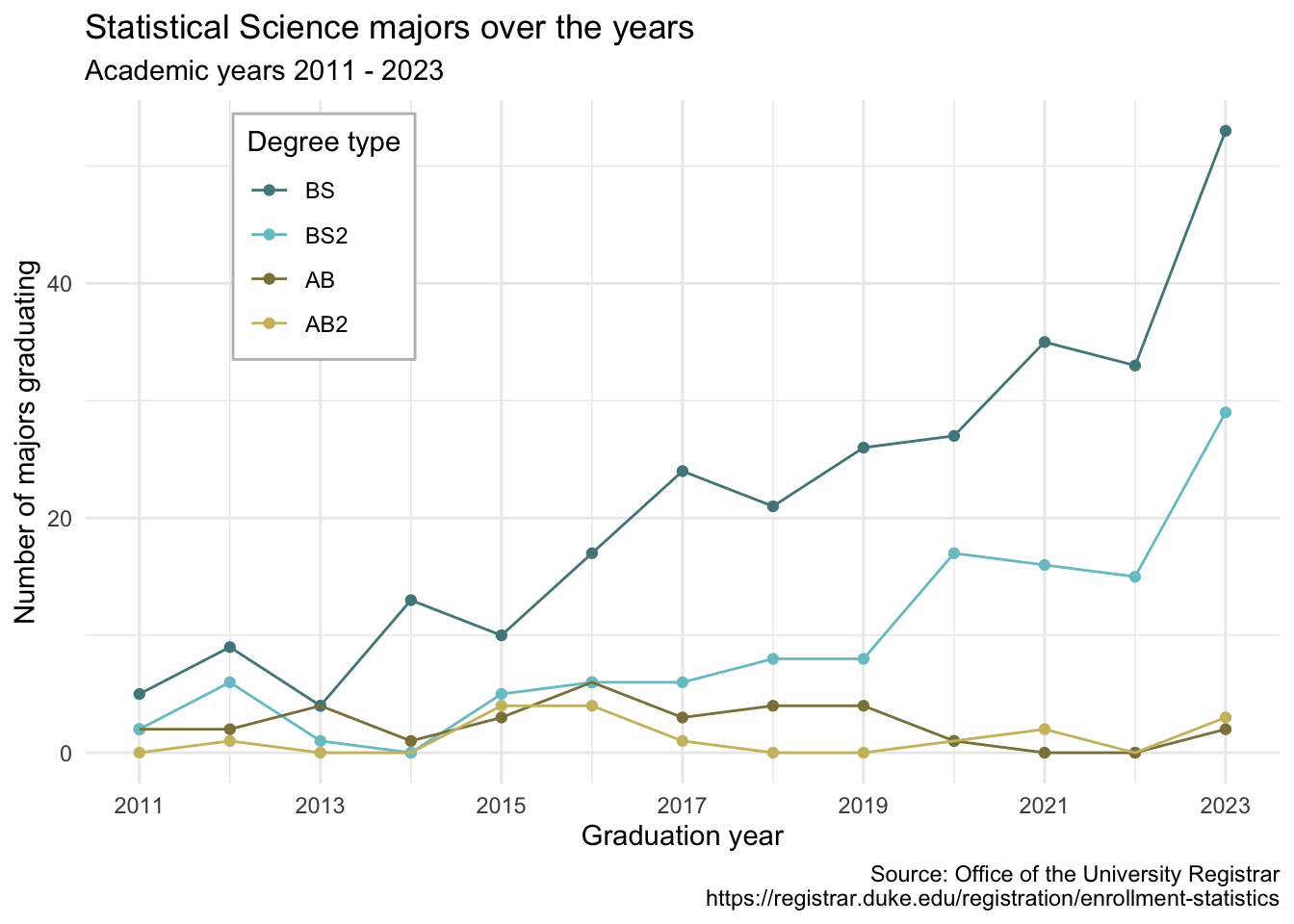
Visualize StatSci majors over the years!
# A tibble: 4 × 14
degree `2011` `2012` `2013` `2014` `2015` `2016` `2017` `2018` `2019` `2020` `2021`
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Statistica… NA 1 NA NA 4 4 1 NA NA 1 2
2 Statistica… 2 2 4 1 3 6 3 4 4 1 NA
3 Statistica… 2 6 1 NA 5 6 6 8 8 17 16
4 Statistica… 5 9 4 13 10 17 24 21 26 27 35
# ℹ 2 more variables: `2022` <dbl>, `2023` <dbl>The first column (variable) is the degree, and there are 4 possible degrees: BS (Bachelor of Science), BS2 (Bachelor of Science, 2nd major), AB (Bachelor of Arts), AB2 (Bachelor of Arts, 2nd major).
The remaining columns show the number of students graduating with that major in a given academic year from 2011 to 2023.
Take a look at the plot we aim to make and sketch the data frame we need to make the plot. Determine what each row and each column of the data frame should be. Hint: We need data to be in columns to map to aesthetic elements of the plot.
ae-05-majors-tidyingGo to the project navigator in RStudio (top right corner of your RStudio window) and open the project called ae.
If there are any uncommitted files, commit them, and then click Pull.
Open the file called ae-05-majors-tidying.qmd and render it.
pivot_longer() function.