# A tibble: 3 × 4
w x y z
<dbl> <chr> <chr> <dbl>
1 1 a c 5
2 2 b d 6
3 3 4 <NA> NA
Collecting data
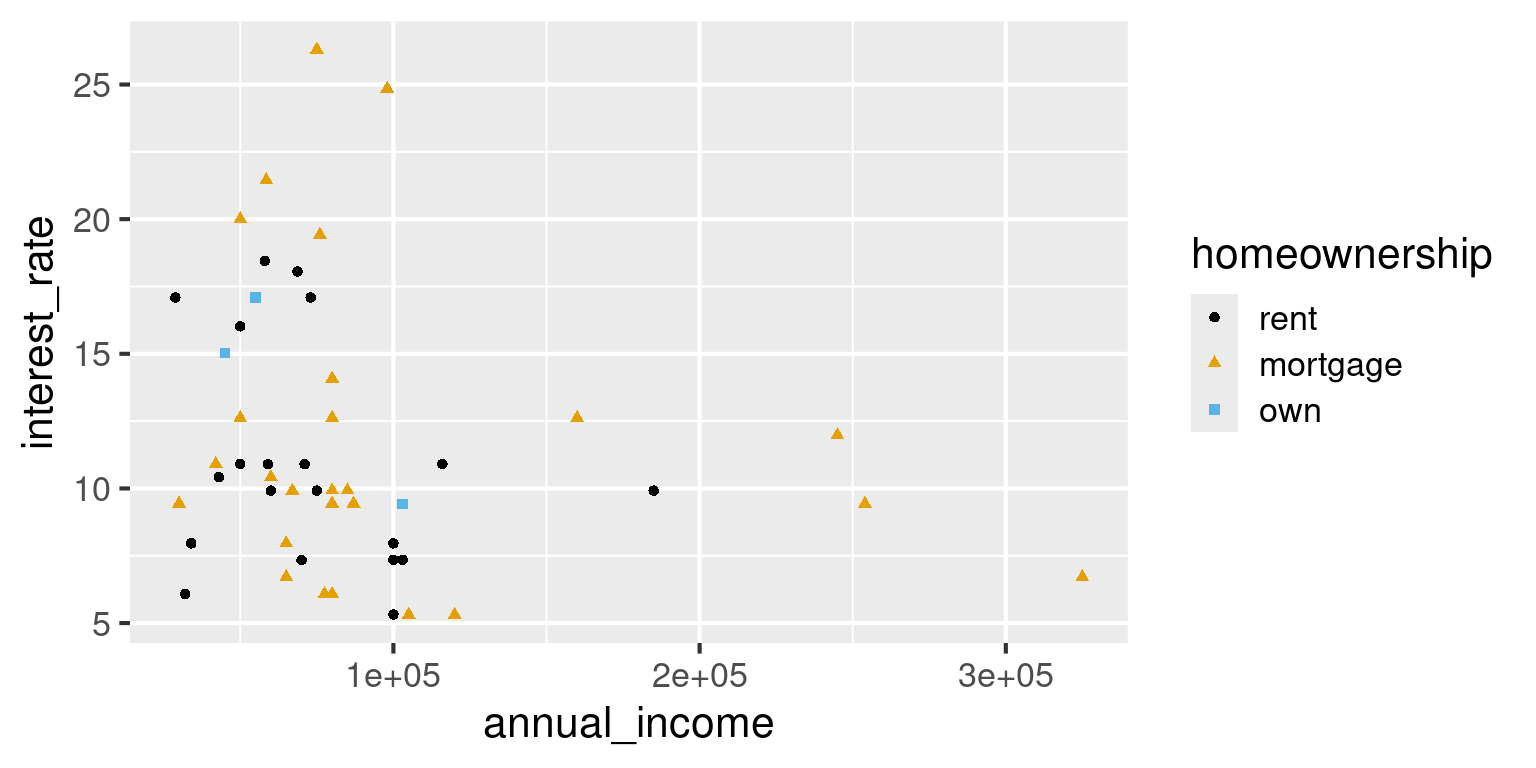
Suppose you conduct a survey and ask students their student ID number and number of credits they’re taking this semester. What is the type of each variable?
survey_raw <-tibble(student_id =c(273674, 298765, 287129, "I don't remember"),n_credits =c(4, 4.5, "I'm not sure yet", "2 - underloading"))survey_raw
# A tibble: 4 × 2
student_id n_credits
<chr> <chr>
1 273674 4
2 298765 4.5
3 287129 I'm not sure yet
4 I don't remember 2 - underloading
# A tibble: 4 × 2
student_id n_credits
<dbl> <dbl>
1 273674 4
2 298765 4.5
3 287129 NA
4 NA 2
Recap: Type coercion
If variables in a data frame have multiple types of values, R will coerce them into a single type, which may or may not be what you want.
If what R does by default is not what you want, you can use explicit coercion functions like as.numeric(), as.character(), etc. to turn them into the types you want them to be, which will generally also involve cleaning up the features of the data that caused the unwanted implicit coercion in the first place.