stop_words <- read_csv("data/stop-words.csv")
chronicle |>
tidytext::unnest_tokens(word, title) |>
anti_join(stop_words) |>
count(word, sort = TRUE) |>
slice_head(n = 20) |>
mutate(word = fct_reorder(word, n)) |>
ggplot(aes(y = word, x = n, fill = log(n))) +
geom_col(show.legend = FALSE) +
theme_minimal(base_size = 16) +
labs(
x = "Number of mentions",
y = "Word",
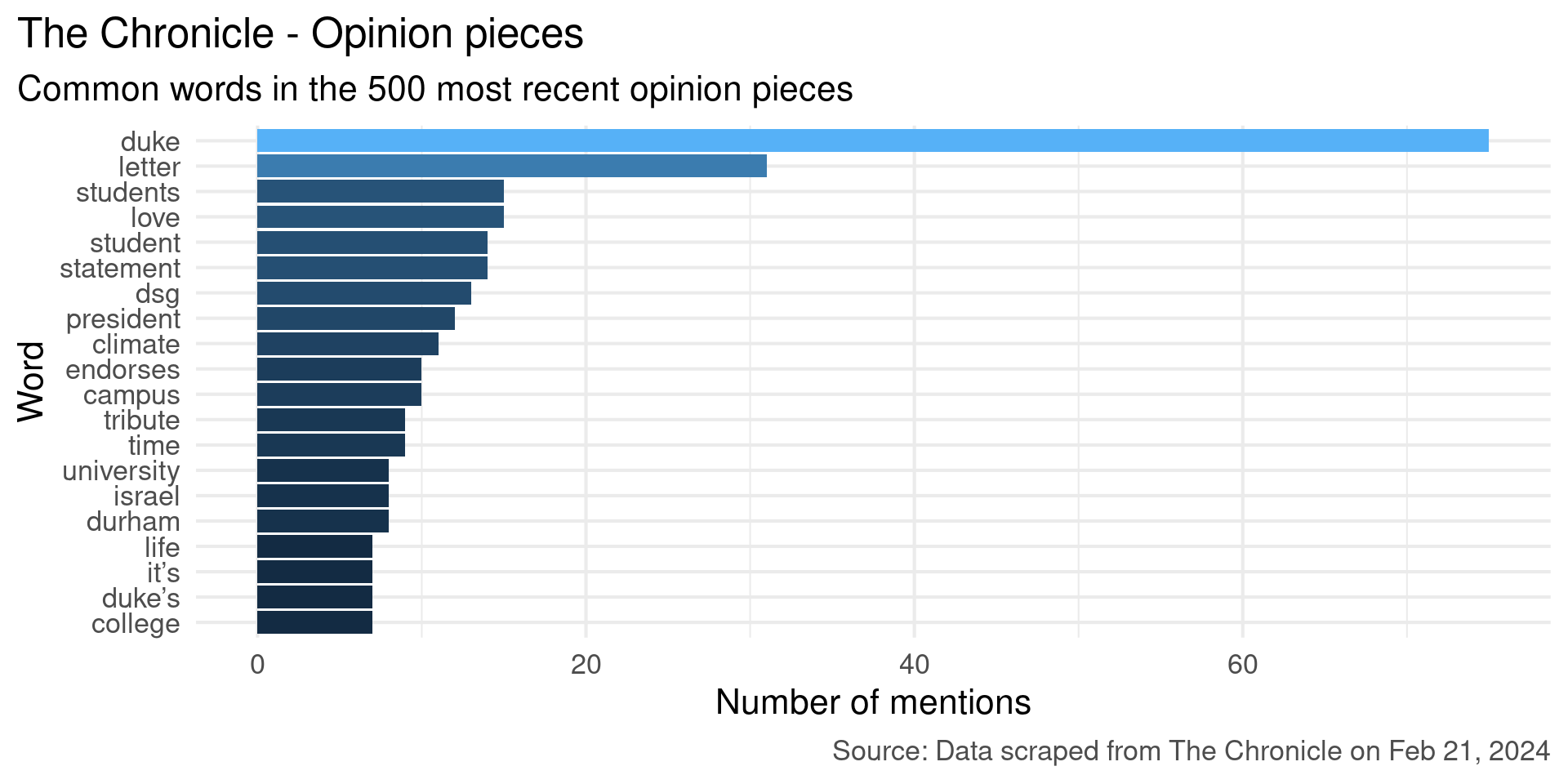
title = "The Chronicle - Opinion pieces",
subtitle = "Common words in the 500 most recent opinion pieces",
caption = "Source: Data scraped from The Chronicle on Feb 21, 2024"
) +
theme(
plot.title.position = "plot",
plot.caption = element_text(color = "gray30")
)Web scraping
Lecture 11
2024-02-22
Analyzing The Chronicle
Analyzing The Chronicle
Where is the data coming from?
Where is the data coming from?
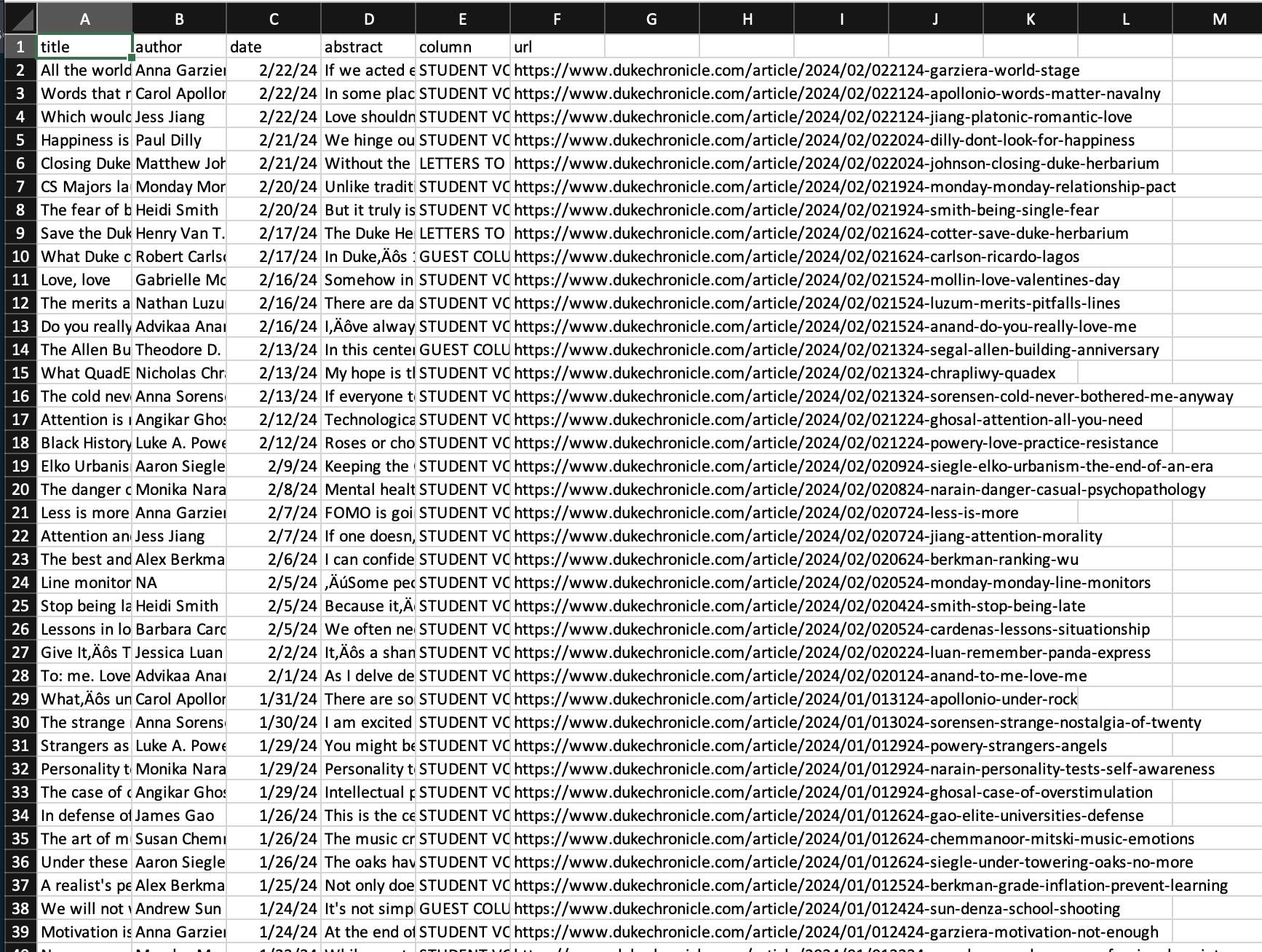
# A tibble: 500 × 6
title author date abstract column url
<chr> <chr> <date> <chr> <chr> <chr>
1 All the world’s a stage Anna … 2024-02-22 If we a… STUDE… http…
2 Words that matter: For Alexei Navalny Carol… 2024-02-22 In some… STUDE… http…
3 Which would you save: Friend or romantic partn… Jess … 2024-02-22 Love sh… STUDE… http…
4 Happiness is not what you’re looking for Paul … 2024-02-21 We hing… STUDE… http…
5 Closing Duke's Herbarium: A fear of long-term … Matth… 2024-02-21 Without… LETTE… http…
6 CS Majors launch 'ambiguous and labelless rela… Monda… 2024-02-20 Unlike … STUDE… http…
7 The fear of being single Heidi… 2024-02-20 But it … STUDE… http…
8 Save the Duke Herbarium Henry… 2024-02-17 The Duk… LETTE… http…
9 What Duke can learn from retiring ex-president… Rober… 2024-02-17 In Duke… GUEST… http…
10 Love, love Gabri… 2024-02-16 Somehow… STUDE… http…
# ℹ 490 more rowsrvest
- The rvest package makes basic processing and manipulation of HTML data straight forward
- It’s designed to work with pipelines built with
|> - rvest.tidyverse.org

SelectorGadget
SelectorGadget (selectorgadget.com) is a javascript based tool that helps you interactively build an appropriate CSS selector for the content you are interested in.
Goal
- Scrape data and organize it in a tidy format in R
- Perform light text parsing to clean data
- Summarize and visualze the data
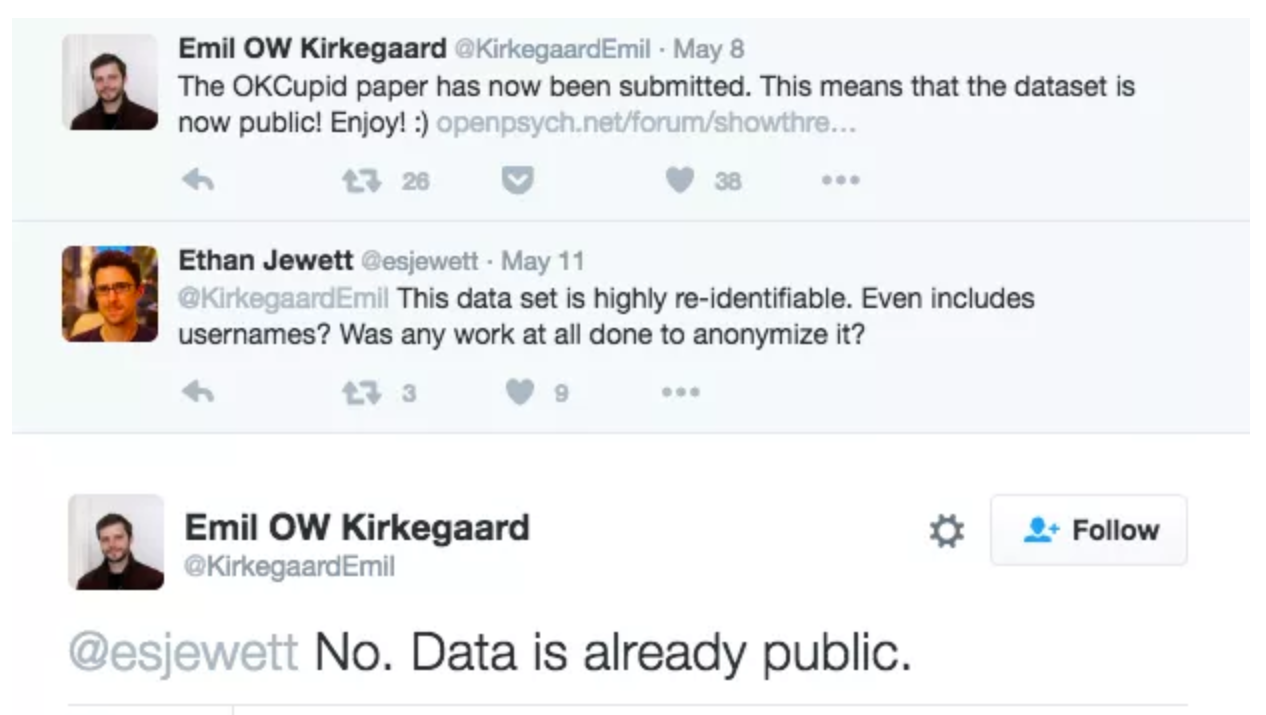
Ethics: “Can you?” vs “Should you?”
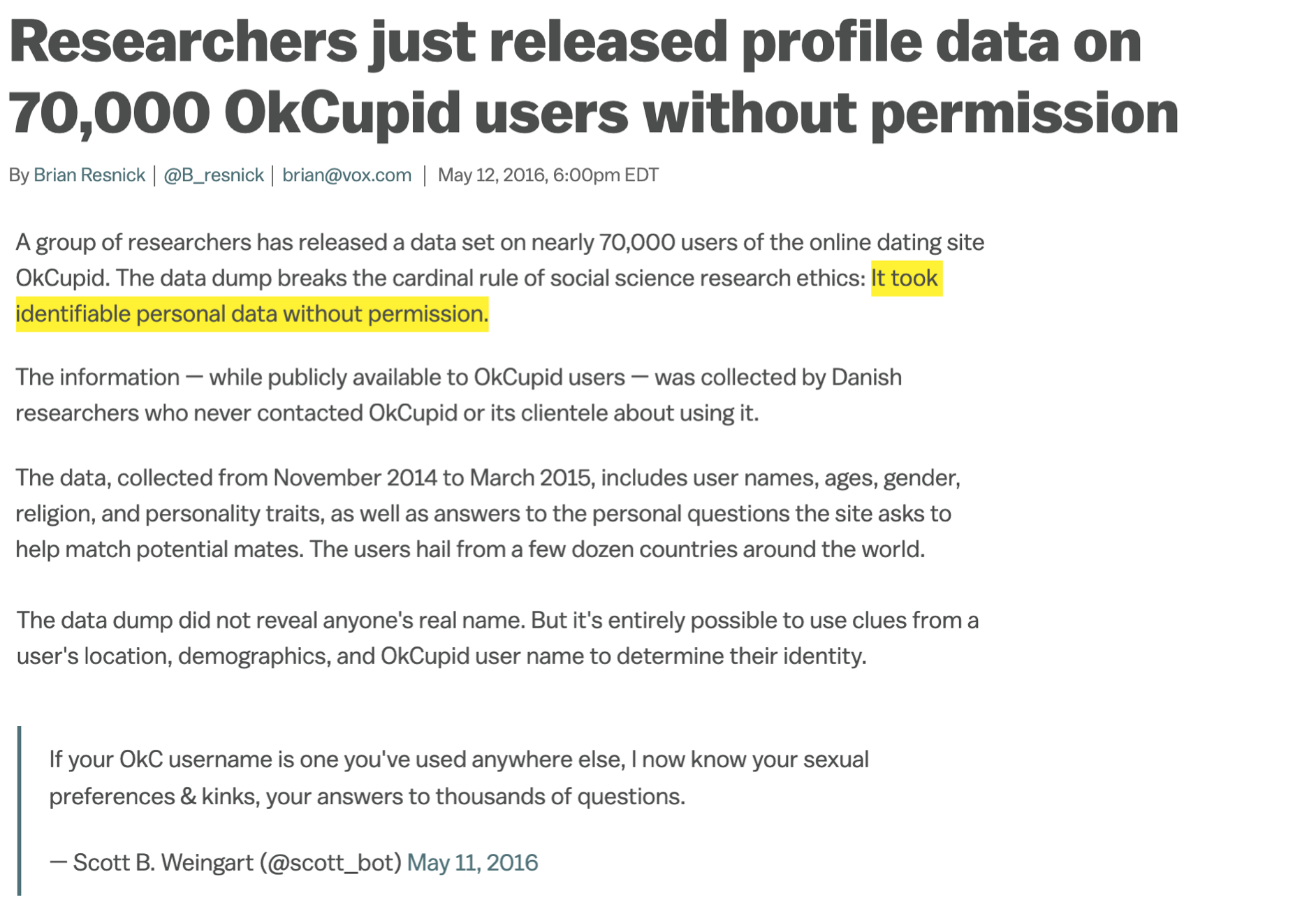
“Can you?” vs “Should you?”
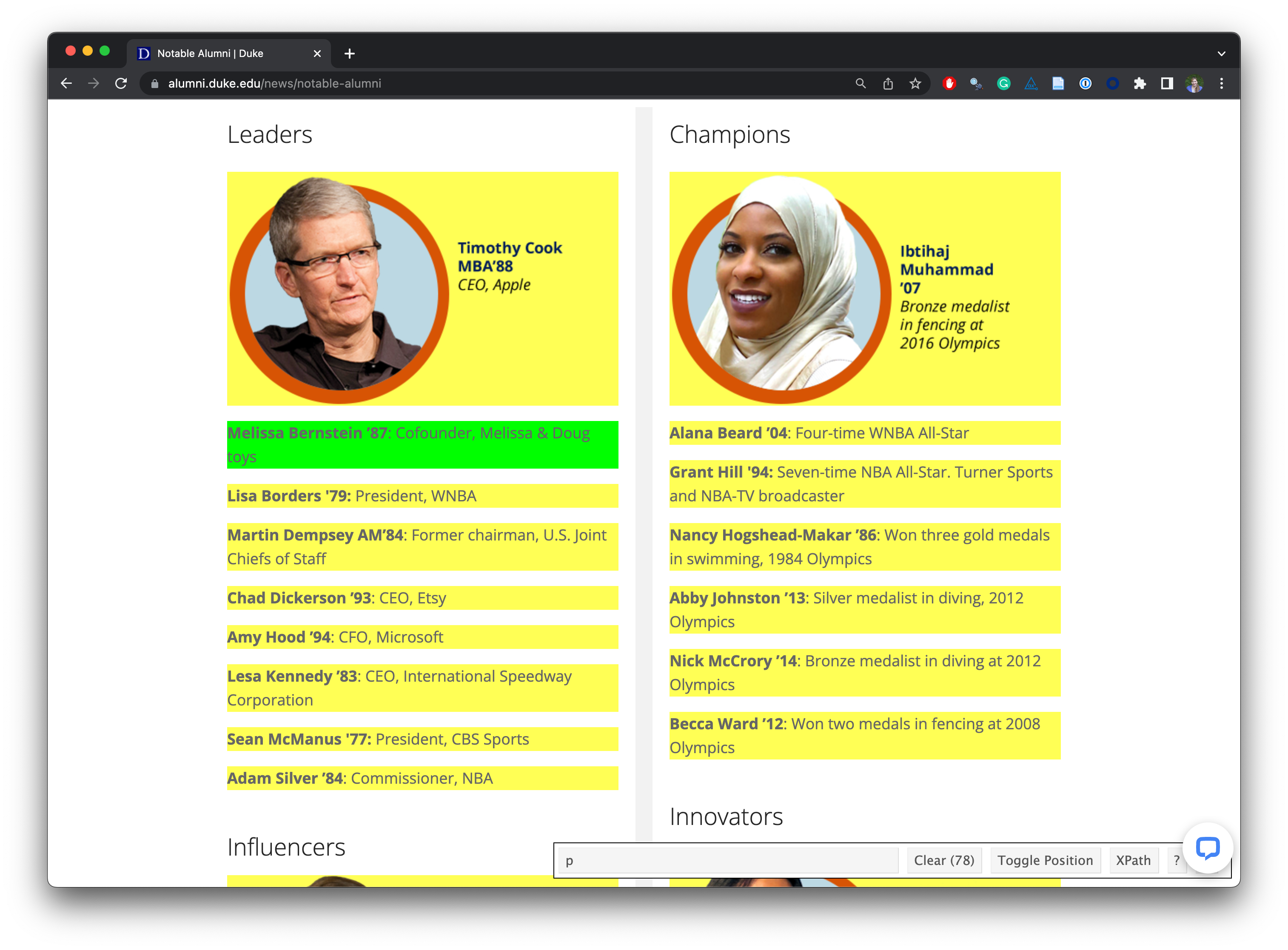
Challenges: Unreliable formatting
Challenges: Data broken into many pages
Workflow: Screen scraping vs. APIs
Two different scenarios for web scraping:
Screen scraping: extract data from source code of website, with html parser (easy) or regular expression matching (less easy)
Web APIs (application programming interface): website offers a set of structured http requests that return JSON or XML files
![]()