Making decisions with randomization tests
Lecture 21
2024-04-04
Trivia
What is this visualization about?
Bootstrap intervals
- Why do we construct confidence intervals?
- What is bootstrapping?
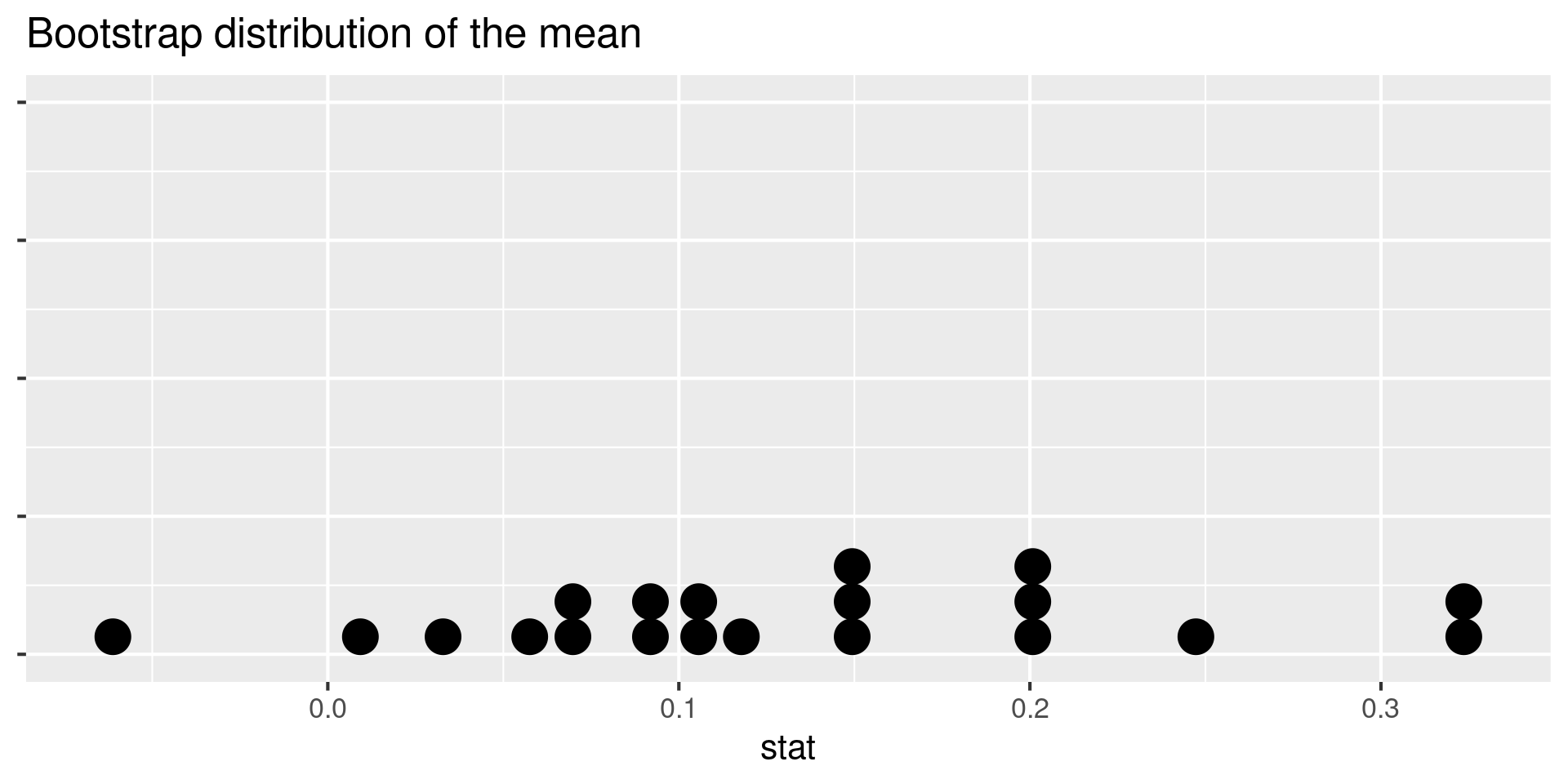
- What does each dot on the plot represent? Note: The plot is of a bootstrap distribution of a sample mean.
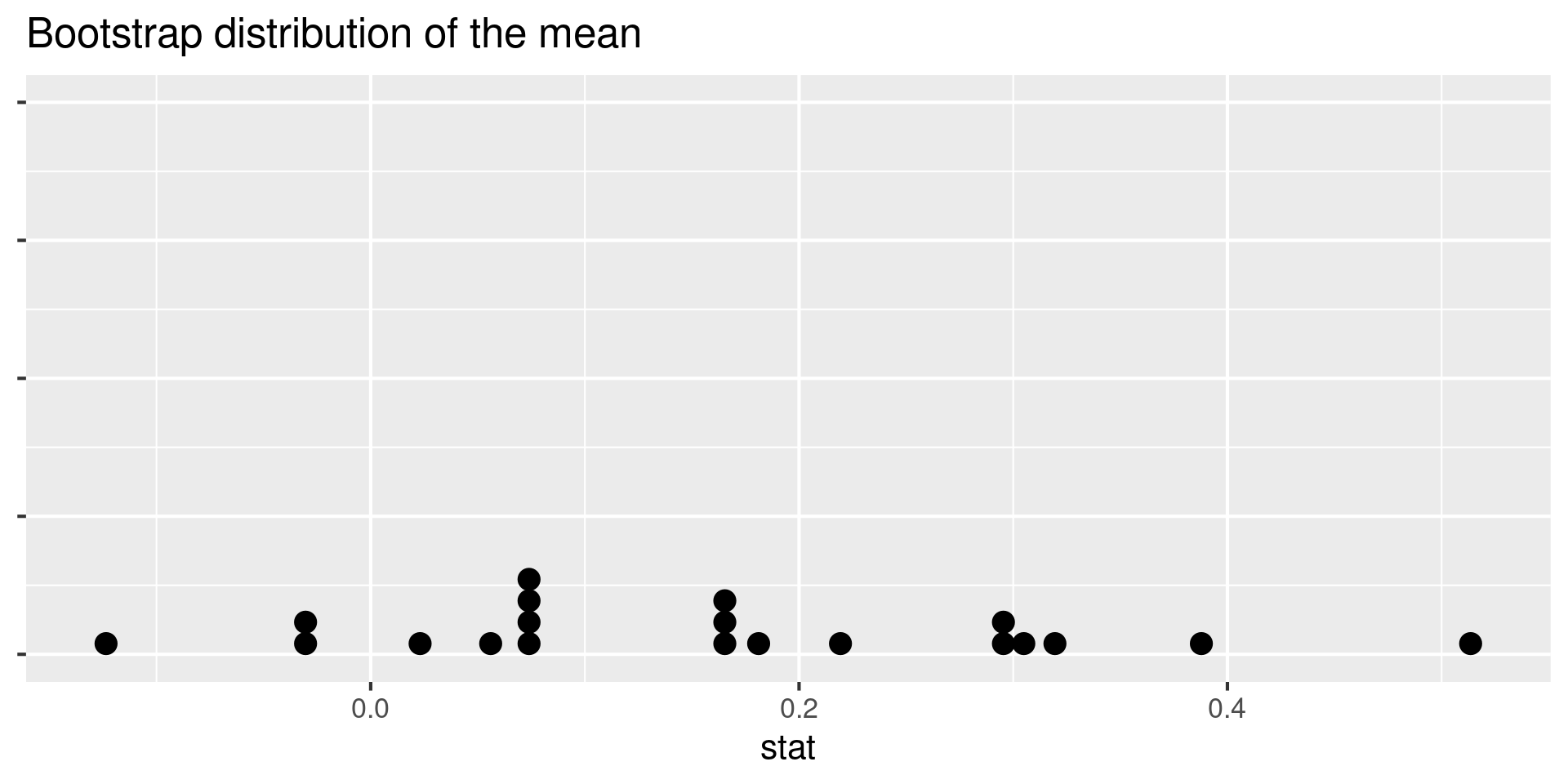
What does each dot on the plot represent?
Note: The plot is of a bootstrap distribution of a sample mean.
- Resample, with replacement, from the original data
- Do this 20 times (since there are 20 dots on the plot)
- Calculate the summary statistic of interest in each of these samples
Recap of AE
- A hypothesis test is a statistical technique used to evaluate competing claims (null and alternative hypotheses) using data.
- We simulate a null distribution using our original data.
- We use our sample statistic and direction of the alternative hypothesis to calculate the p-value.
- We use the p-value to determine conclusions about the alternative hypotheses.
![]()